Enhance LLM Efficiency with LangChain Caching Techniques

In the dynamic world of large language models (LLMs), speed and efficiency are paramount. Kmeleon, staying true to its ethos of pioneering innovative solutions, explores LangChain's advanced caching mechanisms designed to turbocharge your LLM operations.
Revolutionizing LLM Performance through Advanced Caching
Processing requests with LLMs can be time-intensive, a challenge even for the most advanced hardware and paid APIs. This is particularly evident in production environments handling structured data, where repetitive requests are common. To revolutionize this process, caching responses of API calls becomes a crucial strategy, enhancing efficiency remarkably.
LangChain, a leader in LLM technology, has developed robust caching mechanisms compatible with all supported LLM models. This innovation eliminates the need for manual coding, allowing enterprises to benefit from caching effortlessly.
By integrating LangChain's caching solutions, businesses can achieve:
Reduce response times: By caching frequently requested responses, you can significantly reduce the time it takes to process subsequent requests.
Optimize resource utilization: Caching minimizes the load on LLM servers, allowing you to allocate resources more effectively and reduce costs.
Enhance overall performance: By streamlining API calls and optimizing resource utilization, caching contributes to a smoother, faster workflow.
Understanding the Intricacies Caching Strategies
Caching involves storing frequently accessed data in a readily retrievable location, minimizing the need to repeatedly reprocess it. This approach can significantly reduce response times and improve overall system efficiency. The caching strategies particularly well-suited for LangChain pipelines are:
In-memory Caches: These caches store data in the computer's main memory, providing extremely fast access speeds. However, their capacity is limited by the available memory.
Disk-based Caches (SQLite): Disk-based caches, such as SQLite, offer larger storage capacity compared to in-memory caches. However, accessing data from disk is slower than from memory.
Redis Semantic and GPT Caches: These caches go beyond exact-match caching and allow retrieving results for semantically similar requests. This enhances versatility and improves caching effectiveness.
In Memory Cache:
In Memory cache uses RAM memory to store the results of previous LLM calls. For a response to be found and returned by the cache, the prompt must be identical to the previously executed prompt.

The first time you run a test request, it will take longer because the result is not cached yet. The second time you run it, it should be faster because the result is retrieved from the cache.
SQLite Cache:
SQLite caching is a lightweight, disk-based storage option that you can use to store the results of your LLM API calls. SQLite is a popular database engine known for its ease of use and portability.

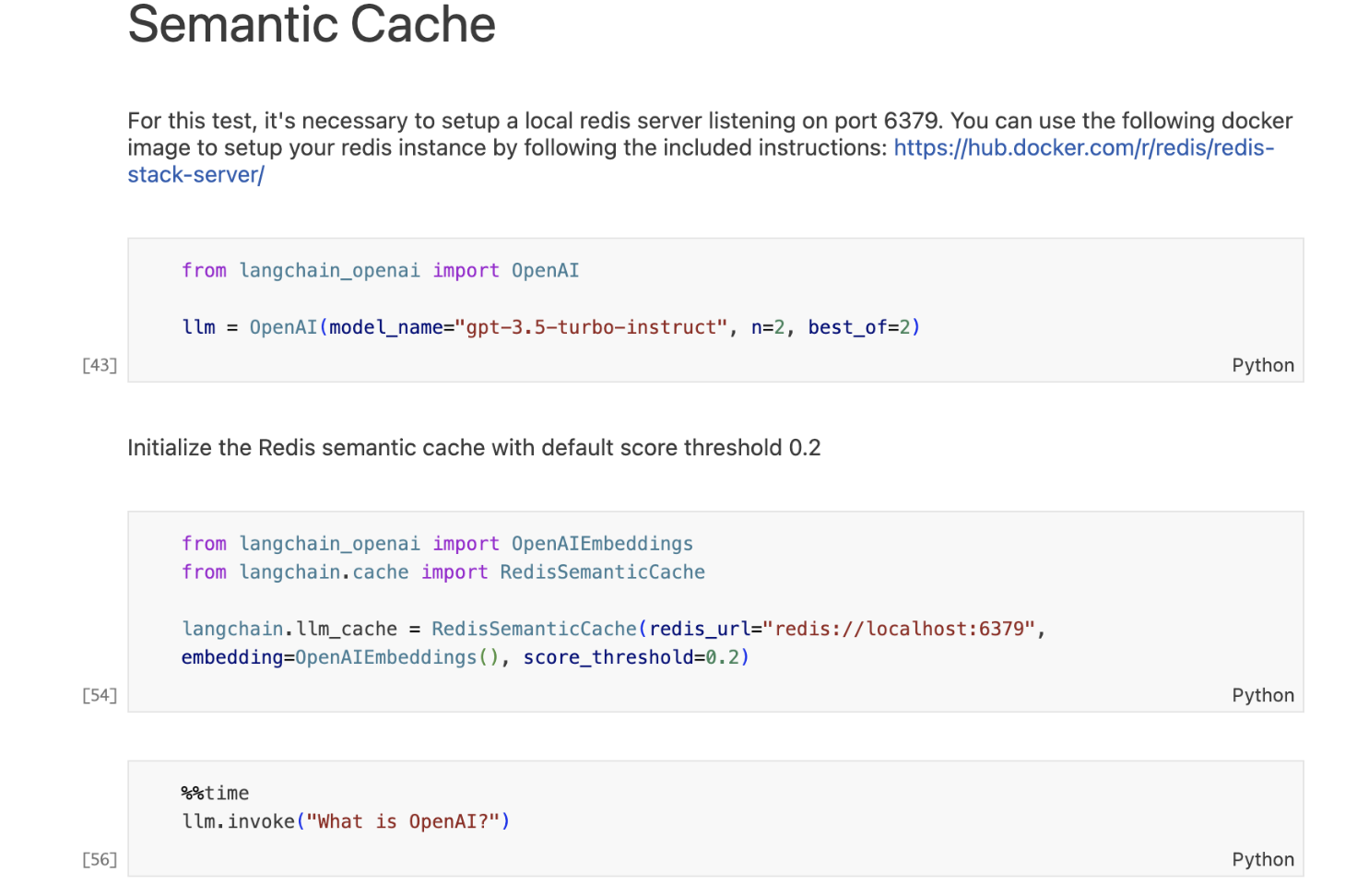
Semantic Cache - Redis
Semantic cache works by first converting a query into a vector representation. This vector representation captures the meaning of the query, rather than its exact wording. The cache then searches for other queries that have similar vector representations. If it finds a match, it returns the cached result for that query.
LangChain has the option of using RedisSemanticCache as a cache that utilizes Redis as a vector-store backend.
Similarity Threshold for Semantic Cache
The similarity threshold parameter is an important setting that determines how similar the user input and cached results must be to retrieve them from the semantic cache. The higher the threshold, the stricter the semantic matching is. The lower the threshold, the more lenient the semantic matching is. The default value of the threshold is 0.2, which means the user input and cached results must have a cosine similarity of at least 0.2 to be considered semantically similar.
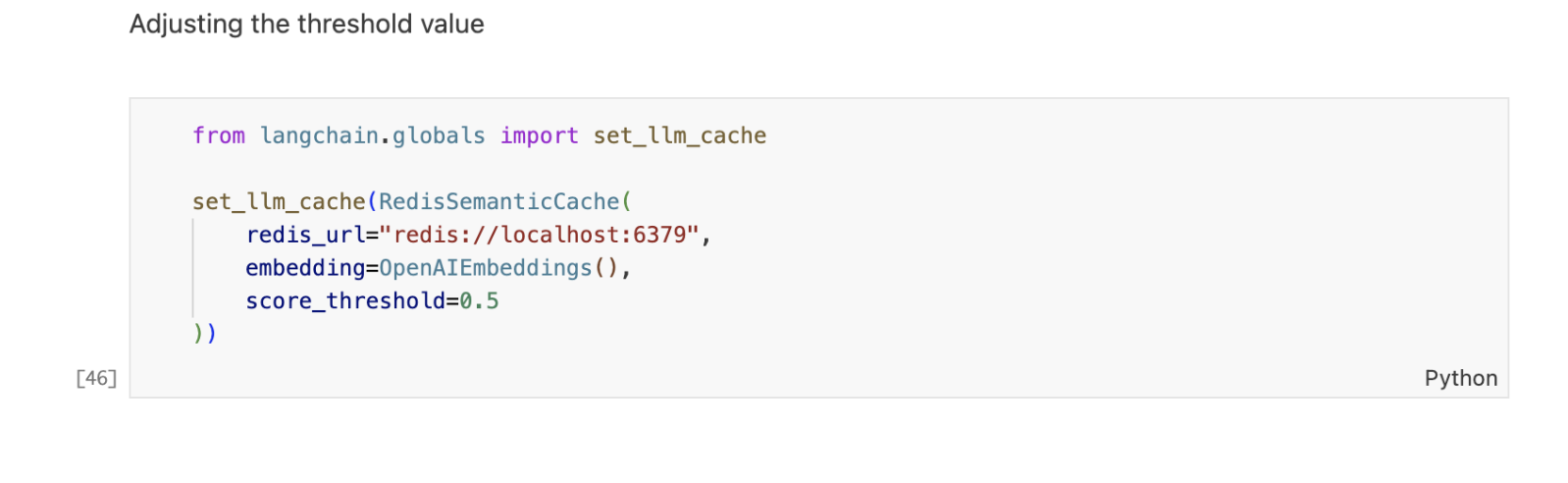
The threshold can be set when initializing the RedisSemanticCache class, which is a cache that uses Redis as a vector-store backend. The RedisSemanticCache class takes three arguments: redis_url, embedding, and score_threshold. The redis_url is the URL to connect to Redis, the embedding is the embedding provider for semantic encoding and search, and the score_threshold is the threshold for semantic caching.
To create a RedisSemanticCache object with a threshold of 0.8, which means that the user input and the cached results must have a cosine similarity of at least 0.8 to be considered semantically similar, one can use the following code:
Semantic Cache - GPTCache
Similar to Redis Semantic Cache, GPTCache is a new caching tool that can improve the efficiency and performance of LLMs by caching results based on semantic similarity.
The idea behind it is the same as the Redis implementation. GPTCache works by first converting a query into a vector representation. This vector representation captures the meaning of the query, rather than its exact wording. The cache then searches for other queries that have similar vector representations. If it finds a match, it returns the cached result for that query.

You can find the source code for these examples in our GitHub repository.
Choosing the Right Caching Strategy
The choice of caching strategy depends on the specific needs and constraints of the LangChain pipeline.
Factors to consider include:
Data Size: If the data volume is relatively small, an in-memory cache may suffice. For larger datasets, disk-based caches or Redis might be more suitable.
Performance Requirements: If low latency is critical, an in-memory cache or Redis is preferable. For less time-sensitive applications, a disk-based cache can be a cost-effective option.
Flexibility: Semantic and GPT cache offer increased flexibility by allowing caching of similar requests. This is particularly beneficial for applications that deal with natural language variations.
Caching strategies play a crucial role in optimizing LangChain pipelines, enhancing their performance, efficiency, and cost-effectiveness. By carefully selecting and implementing appropriate caching techniques, developers can empower their LangChain applications to deliver a responsive, scalable, and cost-effective language processing experience.
Empirical Evidence: Speed Tests Comparison
To gain a better understanding of the behavior of each cache type, we tested all the above-mentioned cache types to compare their speed.
For the tests, two documents were used to perform the embeddings:
Document 1, with 2 pages
Document 2, with 275 pages
Three questions on a specific topic were used in each text, the first two are the same, so we can measure the time in which the cache decreased the response, and the third has the same semantic meaning but with different words, to know if the cache can return results even for requests that are not exactly the same but have similar a meaning and in a shorter time than the original question. These are the selected questions for each document:
Document 1:
Question 1 & 2: "What are the methods mentioned in the document?"
Question 3: "Describe the mentioned methods"
Document 2:
Question 1 & 2: "Describe the principles of insurance"
Question 3: "What can you tell me about the principles of insurance?"
The following table presents the results:

Analysis of the cache type test table
In general, the results of the table show that semantic-based cache types (Redis and GPTCache) provide better performance than non-semantic-based cache types (In Memory Cache and SQLite Cache).
In the 2 paged document, semantic-based cache types are about 30% faster than non-semantic-based cache types. In the 275 paged document, semantic-based cache types are about 50% faster than non-semantic-based cache types.
These results are due to the fact that semantic-based cache types can leverage semantic relationships between words and sentences to find answers that have already been stored, avoiding further LLM calls.
Final Impressions and Recommendations
The test results are encouraging for developers looking to improve the performance of their applications that query large amounts of data. Semantic-based cache types offer an effective way to reduce the response time of these queries. However, it is important to note that semantic-based cache types can also be more complex and expensive to implement than non-semantic-based cache types. Therefore, it is important to carefully evaluate the specific needs of the application before deciding which type of cache is right.
It’s important to experiment with different configurations for the cache parameters to find the set of options that offers the best performance for your application, and to monitor the performance of the cache to detect any problems or performance degradation.
Revolutionize Your Enterprise's LLM Capabilities with Kmeleon
Discover how Kmeleon's expertise in AI can drive your business's digital evolution. Contact us for a tailored GenAI strategy that harnesses the full power of LangChain's caching capabilities. Let Kmeleon be your partner in transforming your enterprise with cutting-edge AI solutions.
References:
LLM Caching integrations, https://python.langchain.com/docs/integrations/llms/llm_caching
Caching, https://python.langchain.com/docs/modules/model_io/llms/llm_caching
How to cache LLM calls in LangChain, https://medium.com/@meta_heuristic/how-to-cache-llm-calls-in-langchain-a599680dadd5
Caching Generative LLMs | Saving API Costs, https://www.analyticsvidhya.com/blog/2023/08/caching-generative-llms-saving-api-costs/
Save time and money by caching OpenAI (and other LLM) API calls with Langchain, https://mikulskibartosz.name/cache-open-ai-calls-with-langchain
Using Redis VSS as a Retrieval Step in an LLM Chain, https://redis.com/blog/using-redis-vss-in-llm-chain/