Choosing the Right LLM For Your Use Case

Large language models (LLMs) are powerful AI systems that can generate natural language texts for various purposes and tasks. They are trained on massive amounts of data and can learn from different domains and languages. However, not all LLMs are created equal. Depending on your use case, speed, cost, size, and fine-tuneability, you may want to choose a different LLM for your project. In this document, we will compare the most advanced LLMs in the market, such as GPT-4, Gemini, PaLM2, Llama2, Mixtral 8x7B, and some others to provide some recommendations for when to use each one.
How do LLMs work?
Traditional Natural Language Processing (NLP) methods and modern Large Language Models (LLMs) like GPT-4 represent two distinct approaches in the field of computational linguistics. Traditional NLP techniques often relied on rule-based systems, where specific grammatical rules and lexicon dictionaries were programmed into the system. These methods required extensive manual effort to cover various linguistic rules and exceptions, making them less flexible and often limited to specific tasks or languages.
In contrast, Large Language Models such as GPT-4 signify a paradigm shift, moving away from rule-based systems to machine learning models trained on extensive datasets. Early language models like GPT-1 had limitations in generating coherent long-form text, often producing nonsensical outputs after a few sentences. In contrast, advanced models like GPT-4 can produce thousands of contextually relevant words. This evolution is largely due to extensive training on vast datasets, typically including a wide range of internet content and numerous books, giving these models a broad base of knowledge to draw from.
These language models operate by understanding the relationships between word fragments, known as tokens, using complex mathematical models involving high-dimensional vectors. Each token is assigned a unique identifier, and tokens representing similar concepts are grouped together. This forms the foundation of a neural network, which is central to an LLM's function.
However, training an AI model solely on open internet content could lead to the generation of inappropriate or irrelevant responses. To mitigate this, LLMs undergo additional training and fine-tuning to steer them towards producing safe and useful responses. This involves adjusting the weights of the nodes in the neural network, among other methods.
In summary, while LLMs might seem like complex 'black boxes,' understanding their basic operational principles helps in comprehending why they are effective in answering a wide array of questions, as well as why they sometimes generate incorrect or fabricated information. Their capabilities and limitations are rooted in their design and the nature of their training data, marking a significant advancement from traditional NLP methods.
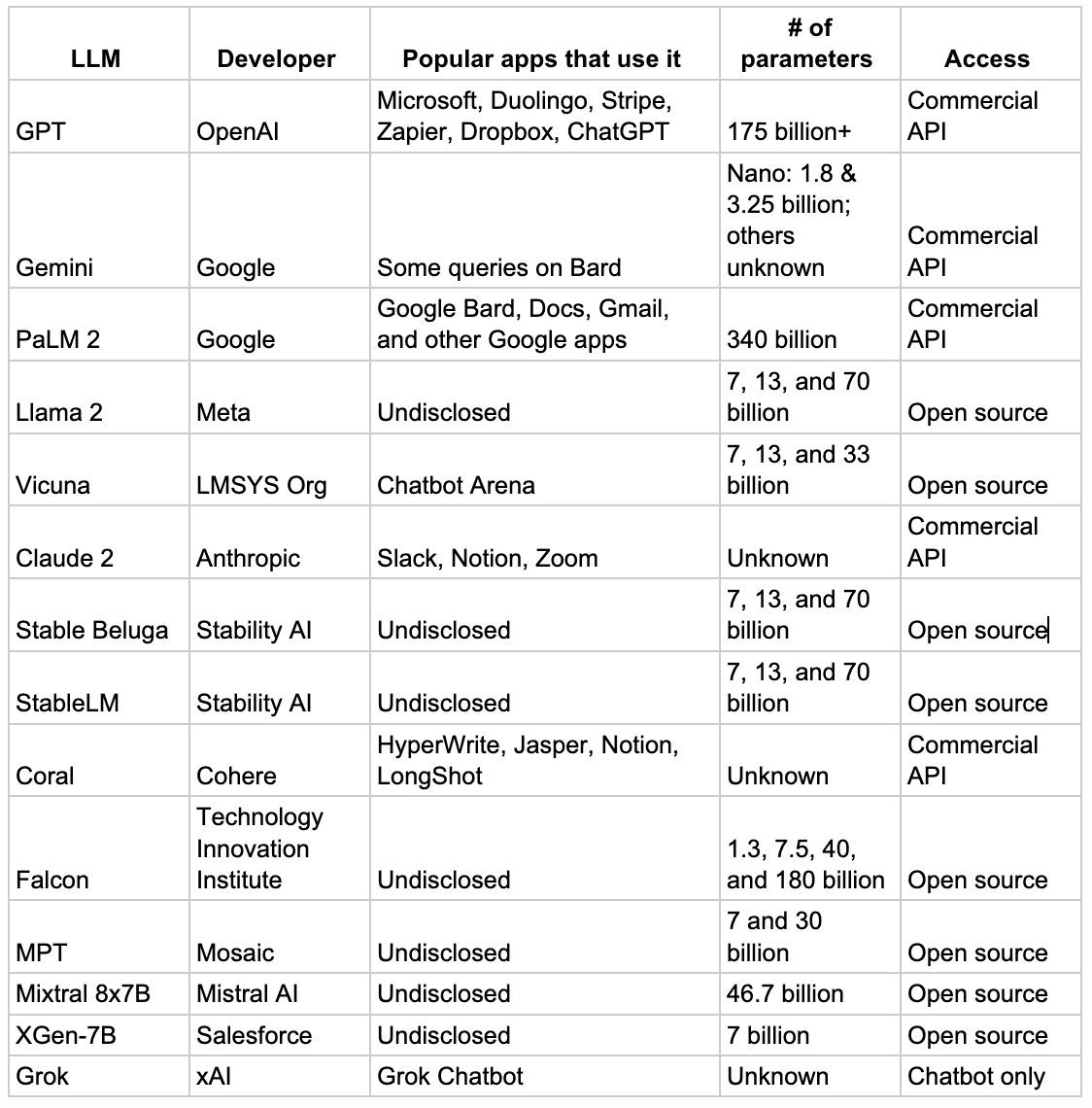
The Most Relevant LLMs of Today
Attempting to catalog every existing LLM would not only be a Herculean task but would also quickly become obsolete given the rapid development in this field.
In curating a list of the most noteworthy LLMs, the term "best" is subjective and should be considered with a pinch of practicality. Our focus here is not solely on the LLMs that excel in benchmarks – although many on this list do – but rather on those that are significant, recognized and simple to implement in your enterprise workloads.
Using Benchmarks to Evaluate LLMs
LLM (Large Language Model) benchmarks are standardized tests used to evaluate the performance of large language models. The number of benchmarks available for general evaluation of LLMs is growing, with multiple benchmarks assessing their skills in coding, language understanding, and more. Despite debates about their reliability, ranking LLMs remains vital for understanding specific LLMs' strengths and weaknesses.
Several benchmarks frequently referenced when assessing LLMs are highlighted as follows:
BIG (Beyond the Imitation Game) -Bench Hard: Introduced by Clark et al. in 2021, this extensive benchmark has over 200 tasks across 10 categories, such as code completion, translation, and creative writing.
DROP (Discrete Reasoning Over Paragraphs): Introduced by Dua et al. In 2019, it’s a 96k-question benchmark, in which a system must resolve references in a question, perhaps to multiple input positions, and perform discrete operations over them (such as addition, counting, or sorting).
HellaSwag: Introduced by Zellers et al. In 2019
MBPP: Features 1,000 beginner-level Python programming problems. It measures the code generation abilities of LLMs. Problems include a task description, solution, and test cases.
MMLU (5-shot): Evaluates LLMs on 57 diverse language tasks in multiple languages, including question answering and translation. Performance is gauged by accuracy and fluency.
TriviaQA (1-shot): Tests LLMs' ability to answer questions using only one training example. It contains 100,000 questions and answers of varied difficulty.
HumanEval: Consists of 164 programming challenges. LLMs must generate Python code based on a given description (docstring). Humans assess the code accuracy. This benchmark encompasses only code prompt assessments.

It’s important to mention that a full-fledged LLM implementation is task-specific and contextual. A summarization task for a medical use case needs to be evaluated differently from a consumer support use case. Therefore, an LLM evaluation requires a unification between task and domain specific benchmarks.
Choosing the right LLM
When choosing an LLM for a new project, it is important to consider the following factors:
Use case: What kind of tasks do you want the LLM to perform? Some LLMs are better suited for certain tasks than others. For example, GPT-4 is generally better at generating text than LaMDA.
Speed: How quickly does the LLM need to generate results? Some LLMs are faster than others, but they may also be less accurate.
Cost: How much are you willing to spend on an LLM? LLMs can range in price from a few cents to several dollars per token.
Size: How much computing power do you have available? Larger LLMs tend to require more computing power to run.
Fine-tuneability: Do you need to be able to fine-tune the LLM for your specific needs? Some LLMs are easier to fine-tune than others due to the lack of training tools in their commercial infrastructure, their size and the availability of their internal weights.
Deciding on the optimal LLM for your organization is a strategic decision of significant magnitude. It requires a balanced consideration of various factors including performance, scalability, efficiency, adaptability, and cost-effectiveness. These are the pillars upon which Kmeleon builds its approach to client solutions. Our expertise lies in providing bespoke guidance, ensuring that your choice in LLM aligns perfectly with your business objectives and the unique contours of your industry.
At Kmeleon, we are dedicated to crafting the future of linguistic interfaces through innovative technology. Our team is ready to assist you in navigating this landscape, offering tailored solutions that resonate with your vision of technological evolution. We invite you to connect with us, to embark on a journey towards a future where AI and language converge, driving your business evolution forward.
References
Google Gemini: https://deepmind.google/technologies/gemini/#introduction
PaLM2: “PaLM 2 Technical Report” by Google (2023)
LLama2: “Llama 2: Open Foundation and Fine-Tuned Chat Models” by GenAI, Meta (2023)
Mixtral 8x7B: “Mixtral of Experts” by Q. Jiang et al. (2024)
GPT-3: "Generating Java Code from Natural Language Descriptions" by B. May et al. (2021)
GPT-4: "Hierarchical Attention for Neural Code Generation" by A. Ramesh et al. (2022)
Llama 2: "Recursive Neural Networks for Code Generation" by J. Devlin et al. (2023)
DistilBERT: "Distilling Code Generation Models for Improved Efficiency and Accuracy" by Y. Li et al. (2022)
RoBERTa: "Dynamic Programming for Code Generation with RoBERTa" by S. Sachdeva et al. (2023)
LaMDA: "Reinforcement Learning for Code Generation with LaMDA" by D. Schwartz et al. (2022)
Palm: "Probabilistic Programming for Code Generation with Palm" by D. Kingma et al. (2023)
TinyBERT: "Template-Based Code Generation with TinyBERT" by Y. Liu et al. (2023)